python pandas DataFrameチートシート
はじめに
- DataFrameオブジェクトはread csvなどの二次元のデータを読み込むメソッドによって生成される
- DataFrameオブジェクトのメソッドの戻り値の多くがDataFrameオブジェクトなので、メソッドチェーンを使用できる
- insurance.csvは
メソッド
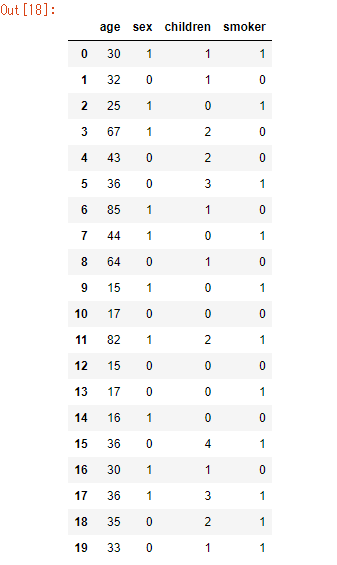
先頭n行を出力 : head()
head(n=5) ---> DataFrame
df.head(n=5)
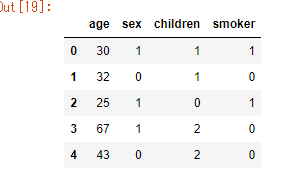
末尾n行を出力 : tail()
tail(n=5) ---> DataFrame
df.tail(n=5)
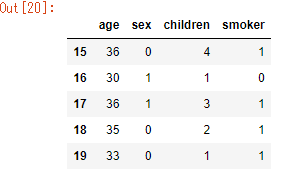
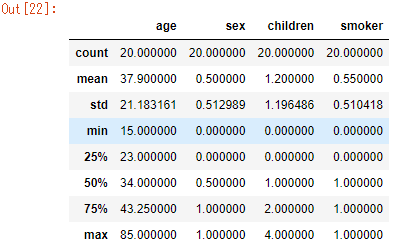
データの各種統計量 : describe()
describe(include=None, exclude=None)---> DataFrame
- デフォルトだと、列の中に数値の列がある場合、intとかfloatのみの統計量が算出される.数値の列が存在しない場合、すべての列の統計量が算出される
- include : 統計量を算出したい列の型を指定。int,[object,bool,int]のように型一つやリストを指定することが可能。'number'とすると数値全てとなる
- exclude : 統計量を算出したくない列の型を指定。includeと同じように指定できる。
df.describe()

df.describe(include='all')
allとすると、すべての列の統計量を算出できます
データの情報: info()
info()———>Nonetype
df.info()

- RangeIndex: 1338 entries, 0 to 1337 : レコード数が1338であることがわかる
- 1338 non-null : nullでない値が1338であることがわかり、レコード数が1338なので、nullのデータが存在しないことがわかる
データの削除: drop()
drop(labels=None,axis=0,index=None,columns=None,level=None,inplace=False,error='raise') ---> DataFrame
| 引数 | デフォルト | 型 | 説明 |
| labels | None | ラベル名orラベル名のリスト | 削除したい行or列のラベル |
| axis | 0 | 0 or 1 | 0 : 行を削除 1 : 列を削除 |
| index | None | ラベル名orラベル名のリスト | 削除したい行のラベル名を指定 |
| columns | None | ラベル名orラベル名のリスト | 削除したい列のラベル名を指定 |
| level | None | 階層名 | マルチインデックスのときのみ有効。 |
| inplace | False | boolean | Trueのとき、直接データが削除される Falseのとき、データは削除されないので他の変数に代入したりして使う |
| error | 'raise' | 'raise' or 'ignore' | エラーを無視するかどうか |
df.drop(axis=1, labels='age')
df.drop(columns='age')
